
No-Bugs No-Glory: Issue no. 1
Logging Quirks on Android
Suppose you wanted to implement encrypted disk-I/O in your application. The way to go about it would be intercept all the I/O system calls and reimplement them so that data written/read will be encrypted/decrypted. One method to intercept those functions would be to hook them. Meaning, set up the process in such a way that when write is called, instead some custom HOOK_write implementation is called. In addition, you might want to know what’s happening inside your functions, so you will naturally use some sort of logging mechanism. In Android’s case you will use the __android_log* API supplied by liblog.so. However, logs are something to be seen by the developers only, and they do add a bit of an overhead to the product, both in size (MiBs) and in performance, so you want to be able to easily switch them off. Surprisingly, a combination of these (rather innocuous) elements can cause some very odd behavior on Android under certain conditions.
Hooks, logs and crashes - oh my!
Now, you have your hooks set-up, your logs in place, everything looks OK, but you encounter weird crashes. These crashes appear only when you turn ON your logs. I have encountered an interesting case in which binary search for the offending log resulted in logs for the hooks for dup2, close and execvpe. The reason for the logs being faulty was not (yet) understood.
Investigation
Examining the crash log revealed the cause of the crash was a Java exception which read as follows (redacted for readability):
java.io.IOException: Cannot run program "chmod": error=456436480, Unknown error 456436480
at java.lang.ProcessBuilder.start (ProcessBuilder.java:983)
...
Caused by: java.io.IOException: error=456436480, Unknown error 456436480
at java.lang.UNIXProcess.forkAndExec (Native Method)
...
As nice as it may be to have the location of the error pointed out to you, it’s not too useful as I did not know what to look for, I needed some more focus. The stack-trace does tell us that the problem was that it could not run the command chmod. Noticing that the names of the classes include ProcessBuilder and UNIXProcess, and the function is forkAndExec, I assumed it did not mean the chmod system call, but the command-line utility /system/bin/chmod. It seemed odd that this utility will be missing, more so odd that it did not seem to pose a problem when logs are turned off. But I tried anyway, I launched a shell on the device and tried to run chmod. It worked, of course.
I figured that if any of the exec* family system calls was called, I should be able to see it in the logs, as we have hooks on them and logs before calling the original exec. Sort of like this:
int HOOK_execve(const char * filename, char * const argv[], char * const envp[])
{
LOG("execve(%s, ...)", filename);
return execve(filename, argv, envp);
}
However, there was no trace in the logs for that ever happening, so I figured the system must not have gotten that far. Then what I want to know now is what happened to prevent exec from being called. If you’ll recall, in POSIX systems, the way to launch a new process is to first fork, then exec in the child and wait in the parent for a SIGCHLD:
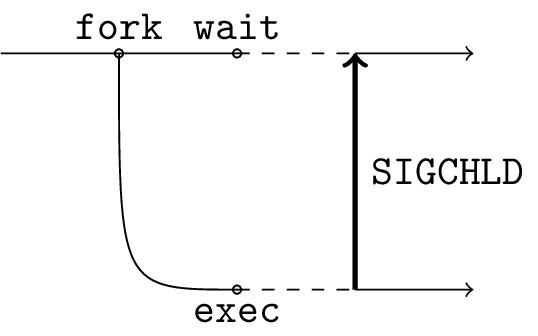
I placed a hook on fork, with a log before and after the original fork:
pid_t HOOK_fork(void)
{
pid_t pid = -1;
LOG("Before fork(). pid=%d", getpid());
pid = fork();
LOG("After fork(). pid=%d, ret=%d", getpid(), pid);
return pid;
}
And the same on wait4 (all wait variants eventually use wait4). And just as expected, I saw 3 log lines for fork (one before the fork, and two after it - child and parent), and a log line for wait4. The conclusion was that fork did happen, but it did not reach exec. The plot thickens…
I began suspecting (naturally) that some log lines are being dropped, maybe as a sort of a throttling or caching mechanism. Usually what people will do at this stage is to modify the LOG function to write into a file on the SDCard, which later can be pulled and examined off-line. I found this method slightly cumbersome, so instead what I did was launch a listening netcat on my machine (nc -l 1337), and have the LOG function write to a socket connected to my machine:
void LOG(const char * fmt, ...)
{
va_list ap;
va_start(ap, fmt);
__android_log_vprint(ANDROID_LOG_INFO, "DEBUG", fmt, ap);
log_to_socket(fmt, ap); /* ADDED THIS */
va_end(ap);
}
Now I should be able to see all the logs, without exceptions. I launched the application, examined the logs, but saw the same thing: fork, wait4, but no exec.
However, this time around, though the contents of the log did not change, I did (change), or more precisely, my perception got keener. What I noticed was that the last log line in the child process was a close. In fact, there was a whole bunch of them in succession. I thought, that if my socket is in that list of close(s), it would make sense that I stop seeing any log traffic. This is easy to verify, just log the fd of the logging socket after creating it and see if that fd is closed. Lo-and-behold, the socket’s fd was in fact the last one closed in the child.
This is very odd though, why would something in the process close my socket??? In any case, this is an easy fix, since I know the fd of the socket, and I control the behavior of close (hooks FTW), I can set it up so that if someone tries to close my socket, I’ll just not do it, and report that I did:
/* logging.c */
int log_socket = -1;
void log_init(void)
{
...
log_socket = socket(AF_INET, SOCK_STREAM, 0);
...
}
/* hooks.c */
extern int log_socket;
int HOOK_close(int fd)
{
if (fd == log_socket) return 0; /* These are not the droids you're looking for */
return close(fd);
}
With the new Band-Aid in place, I was excited to finally be able to see those exec logs…And I did! exec was in-fact called. Just to verify it was “in-fact” being called I placed a log before and after the call to the real exec and I just saw the first one, which means the exec did succeed. But then, why does the Java framework think it failed?
In my puzzled state, I started just adding logs everywhere (haven’t we all been there?) to try and make sense of what’s going on there, and while doing that I decided that since my new logging channel is doing so well, I can do away with the adb log, so I commented out the __android_log_vprint from the LOG implementation. This caused the application to work again. Well that’s Unexpected…
To me this was a dead giveaway that something the logging library does is the source of the problem, but I had no concrete direction. What I did have though was a name, the name from the Java stack-trace. So I decided it’s about time I find that source code and try to make some sense of it. Using androidxref I quickly found the implementation of forkAndExec in /libcore/ojluni/src/main/native/UNIXProcess_md.c. The code is pretty well written and documented, so it was not hard to understand how it works.
The main thing that the implementation addresses is that the parent process has no way of knowing whether the exec succeeded or not. What Java actually does, is create a pipe before the call to fork, then in the child set the write end of the pipe to O_CLOEXEC (close-on-exec, meaning, the kernel should close this fd when performing exec), call exec, and after the exec (which should only happen in case of failure) write the errno into the pipe. Meanwhile, the parent blocks on reading from the pipe. If exec succeeds, the pipe should close and 0 bytes should be read. However if exec fails, there should be 4 bytes waiting in the pipe indicating the reason for the failure. Clever.
So, we already know what happened from the start, the stack-trace told us, the exec failed with errno = 456436480 (=0x1b34ab00). This is unlike any errno I know of. A Google search and an androidxref search confirmed it. Something here is clearly broken. Something or someone is clearly writing into that pipe, so maybe if I had the contents of the pipe it could point me at who is writing there, and WHY!
In order to catch the correct read I had to get creative. The problem was that I don’t know which fd belongs to the read end of the pipe. I could put a hook on pipe and then save the fd to some global variable and use that to determine the correct read. But what if there are several pipes? This seemed like too much work and code to write, and I really did not feel like it. What made this read unique was that it read 4 bytes, so I could use that as an indicator.
Another problem is how to read from the pipe. If I read too large a chunk then the read will block and I won’t get to know what’s in there. I could use poll and the like, but again, too much work, so I went for the simple solution of reading 1 byte at a time.
So I ended up with this monstrosity:
ssize_t HOOK_read(int fd, void * buffer, size_t len)
{
if (4 == len) return read(fd, buffer, len);
while (true) {
char c = '\0';
(void) read(fd, &c, sizeof(c));
if (isalnum(c))
LOG("%02x %c", c, c);
else
LOG("%02x", c);
}
}
About the while (true), I did not care if there program would hang, it would have crashed anyway, I just wanted to know what’s in that pipe.
Now, it was time to look at what’s in that pipe, and voilà: it’s the log itself! Just a quick reminder, I had two log channels, one on my machine to catch all the logs, and another using __android_log_vprint to actually trigger the crash. What I saw in the pipe must have been the log sent via liblog. So I went back to the code of forkAndExec to really understand what’s going on, no detail overlooked. The logic can be roughly broken down to 2 “phases”, a setup, and then an execution phase which can succeed or fail.
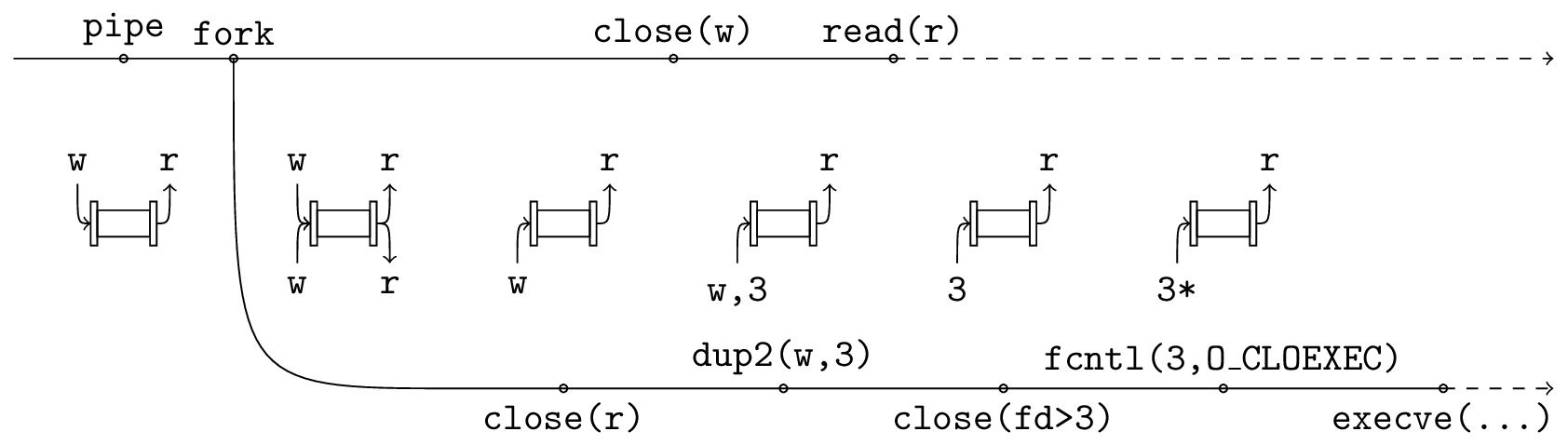
The setup creates a state in which the child and parent are connected via a pipe, where the write end of the pipe is a constant fd=3 and it’s set to O_CLOEXEC. And the parent blocks on reading from that pipe. Now the child is ready to exec. Two things might happen:
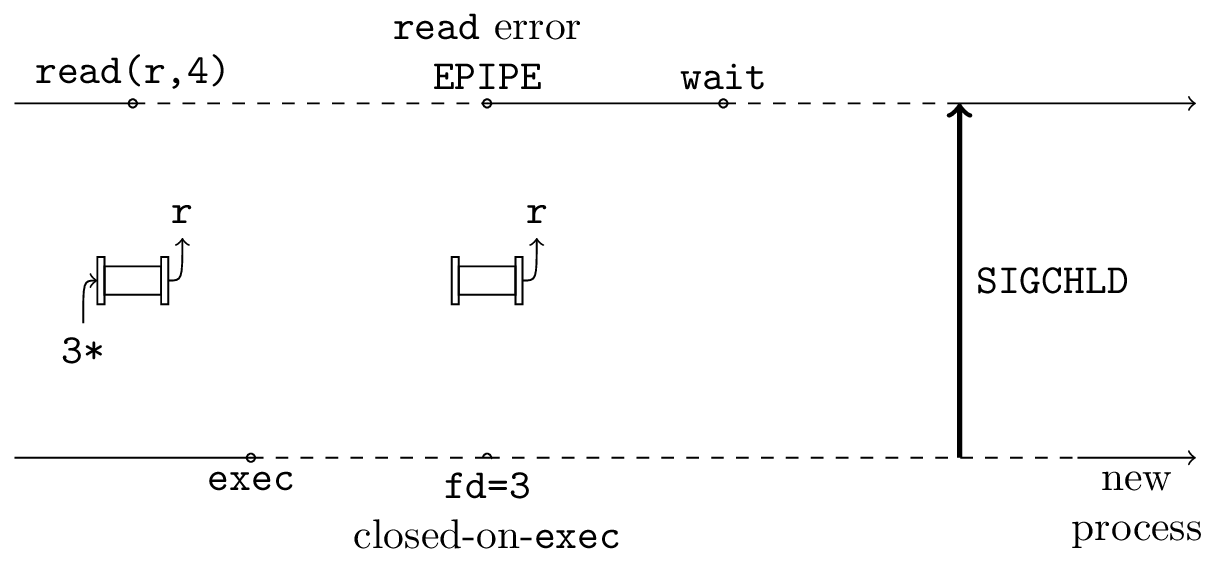
exec succeeded: All the file descriptors marked to close-on-exec will be closed, which means that the write end of the pipe closes. This kills the pipe. The parent’s read returns with a read error. The parent can then wait for the child to finish the exec and transition into the new process.

exec failed: No fds were closed, so the pipe still functions, so the child writes the error code into the pipe so the parent can report what went wrong. The child then _exits. So to summarize, as far as the parent is concerned: Stuff in the pipe means error, broken pipe means everything is good.
This is where it finally clicked for me. The logging facility on Android works by writing/sending a message to a device driver. On older Android versions it’s /dev/log/main while on newer it’s /dev/socket/logdw. The important thing though is that it boils down to a writev into an fd. Now, it makes sense that the logging library would be one of the first libraries loaded and have its initializer called. This means that when that socket is about to be created, there are only 3 occupied fds: 0=STDIN_FILENO, 1=STDOUT_FILENO, 2=STDERR_FILENO, so the socket will be assigned the next available fd: 3.
Back to forkAndExec, when the child process dup2s the write end of the socket, nobody notifies the log library that its socket no longer exists, so when someone (I) invokes __android_log_vprint, it happily writes into the fd it cached, which so happens to be 3(???), but now it’s not a socket, it’s a pipe. The fact that we had logs in the hooks on all the functions called within the child meant that we put garbage in the pipe, making it seem to the parent like the child’s exec failed when it did not.
Solution
To fix the problem we need to implement our own logging mechanism which is separate from the one in liblog.so. We also want the sockets/file-descriptors used in the above implementation to:
- Not be fd=3
- Stay open even when someone is trying to close them
I will leave the implementation details to the reader.
Conclusions
Communicate with your peers
It’s important to have active and open conversations with peers about what it is that you do. Had I not talked to other dev team members, and not known about similar issues, I would have never made the connection between the two problems.
Know your platform
I don’t believe this need any further explanation. Knowledge with the Linux system calls and with Android’s logging mechanism were clearly required in this case. Learn about your platform and tools constantly.
The fact I was familiar with Android’s logging mechanism was only due to the fact that at some point in time I decided to read its code, for research. Which leads me to the next point.
Read the code (RTFC?)
If you already have source code available, you might as well read it, and read it carefully. Maybe if I had read it more carefully from the get-go, I would have discovered the problem sooner.
It’s nearly always your fault
It’s always easier to blame something else: “It’s the system’s fault”. This can make you look for the problem in the wrong places and waste precious time.